Introduction¶
The concept of the SED fitter is very simple: consider a set of sources to be studied. For each source, the SED fitter can fit models, such as model stellar photospheres, YSO model SEDs, as well as galaxy and AGB templates, to the multi-wavelength photometry measurements of this particular source using linear regression.
The scale factor 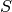 (which is related to the luminosity and distance of
the sources) and the extinction
(which is related to the luminosity and distance of
the sources) and the extinction 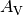 are used as free parameters
in the fitting process. The result for any given source is a value for the
goodness of fit and best-fit values and for every
single model. These fits can then be analyzed to derive properties of the
source.
are used as free parameters
in the fitting process. The result for any given source is a value for the
goodness of fit and best-fit values and for every
single model. These fits can then be analyzed to derive properties of the
source.
To quantify the goodness/badness of each fit to each source, we calculate the
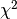 value:
value:
![\chi^2=\sum_{i=1}^N \left(\frac{\langle\,\log_{10}{[F_{\nu}(\lambda_i)]}\,\rangle-\log_{10}{[M_{\nu}(\lambda_i)]}}{\sigma(\langle\,\log_{10}{[F_{\nu}](\lambda_i)}\,\rangle)}\right)^2](_images/math/9349a8ecd0a0d24879abf8cf7a3f882d7caea348.png)
where ![\langle\,\log_{10}{[F_{\nu}(\lambda_i)]}\,\rangle](_images/math/3852d67bbbf592b96e8065f51915216bf4b47eb3.png) are the mean
fluxes in log space, flux values at a given wavelength
are the mean
fluxes in log space, flux values at a given wavelength 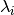 ,
,
}\,\rangle)](_images/math/74eb06faafd8eccb444c9b1366b5cebb4870da33.png) are the flux
uncertainties in log space, and
are the flux
uncertainties in log space, and ![\log_{10}{[M_{\nu}(\lambda_i)]}](_images/math/dddfe8559f0f0803476b2640d887268e3eab9bd3.png) are the
extincted and scaled model log fluxes. For more details, see Robitaille et al
(2007). In this manual we
sometimes refer to the per datapoint,
are the
extincted and scaled model log fluxes. For more details, see Robitaille et al
(2007). In this manual we
sometimes refer to the per datapoint, 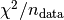 , where the number of datapoints does not include upper and lower
limits.
, where the number of datapoints does not include upper and lower
limits.
The SED fitter uses the concept of model packages, which are single directories containing SEDs, convolved fluxes, parameters, and a description of the models, all in a common format. There are two kinds of models that can be used with the SED fitter:
- Models for which the absolute distance cannot be determined from the fit (e.g. unscaled stellar photosphere models). This is usually used for the purpose of filtering out a certain class of sources, for example foreground/background stars.
- Models that are absolutely scaled in flux, to a distance of 1kpc. In this case, it is also possible to specify fluxes as a function of aperture - in this case, the fitting procedure is more complex as it involves computing the aperture-dependent SEDs for a fine grid of distances, and optionally removing models that would clearly be extended relative to the aperture chosen. This is described in more detail in Robitaille et al (2007).